是机遇还是风险|探索AICG对内容创作的冲击
2023-04-19
前言:AICG通过近几年的野蛮生长,已经于今年初成功破圈,并且引起了圈层地震。近段时间以来,AI工具的表现已经足以说明,其真的可能取代世界上最有才华的一群人类——创作者。
如果你对此嗤之以鼻,认为现在的人工智能还没有完全长成,只能说明你还没有认识到问题的严重性。
是机遇还是风险|探索AICG对内容创作的冲击
2023-04-20 18:25:39
前言:AICG通过近几年的野蛮生长,已经于今年初成功破圈,并且引起了圈层地震。
近段时间以来,AI工具的表现已经足以说明,其真的可能取代世界上最有才华的一群人类——创作者。如果你对此嗤之以鼻,认为现在的人工智能还没有完全长成,只能说明你还没有认识到问题的严重性。
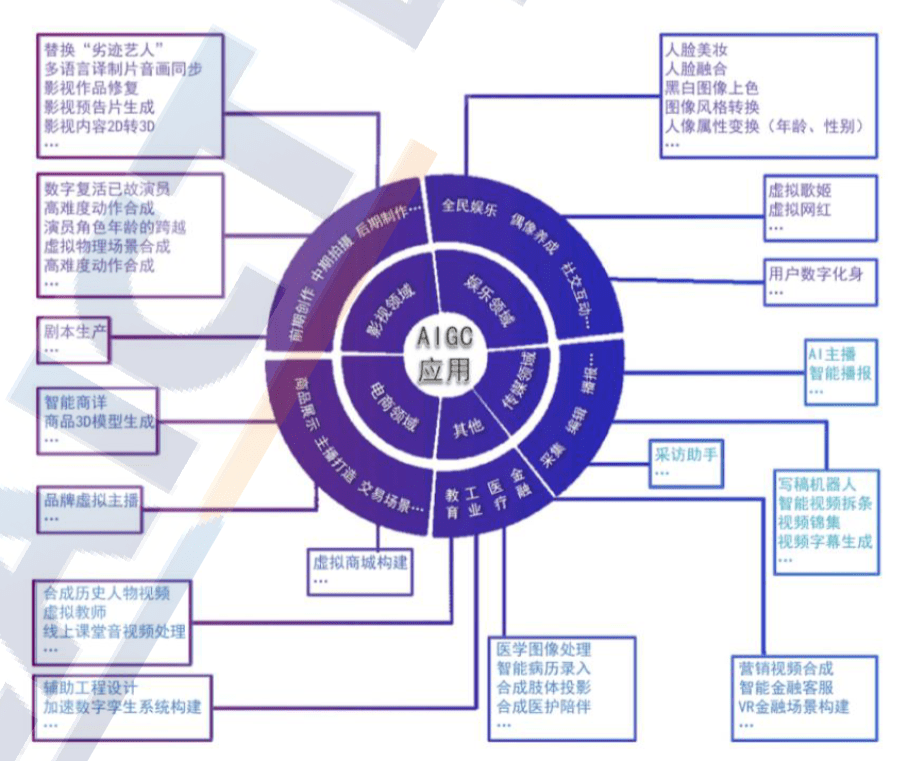
2021年之前,AIGC已经可以生成比较完善的文字内容。2022年,AIGC进入高速发展阶段,随着开源系统不断地对商业化的可能进行探索,其大模型被不断完善,到现在为止,新一代模型可以处理的格式内容已经包括:文字、语音、代码、图像、视频、机器人动作等等内容。
相较于此前的专业生产内容(PGC,professional-generated content)、用户生产内容(UGC,User-generated content),高速迭代的AIGC,已经在创意、表现力、传播、个性化等方面,充分展现出了其强大的技术优势,已经对创作领域完成了一次又一次冲击。
人鬼情未了,从语音对话到视频沟通
去年十月,外网上线了一个完全由AI生成的博客podcast.ai,它的设置也很有意思,每周都会深入探讨一个新话题。

而更让人意想不到的是,第一次节目就给了观众一个大大的“惊喜”。
已故的乔布斯“死而复生”成为了节目的首位嘉宾,为大家上演了一处“人鬼情未了”的海外现场版,和美国知名播客主持人 Joe Rogan 进行了一场长达20分钟的对话。
谈话内容包括但不限于其对的大学生活、对计算机的看法、工作状态以及信仰等等。
当然,这段采访其实是podcast.ai利用在网络上收集到的所有关于乔布斯的录音,加上乔布斯的传记作为素材,利用Play.ht 的语言模型进行了大量训练之后,生成的的一段“假的Joe Rogan 对乔布斯的采访内容。”
2023年2月,乔布斯再次复活,而这次已经不只是音频了,一个活灵活现的乔布斯真实出现在了作者的视频当中,对着镜头侃侃而谈,而谈话的内容,正是今年大火的ChatGPT。
根据原作者所说:视频中的文案选自于他与ChatGPT的对话,乔布斯的形象由AI作图工具Midjourney生成,AI拟声工具ElevenLabs提供了嗓音复刻,最后通过AI视频工具D-ID将图像转为视频。
这说明了AI已经越来越多地进入了内容创作的过程当中,甚至已经能够包揽文案、录制、配音、剪辑等一般视频创作的全部工作。

AI自动生成视频,让图片动起来
“D-ID”是一个利用图片生成数字人/虚拟分身的AI工具,凭借其强大的图像处理技术,以及对神经网络进行的大量训练,已经具备了非常逼真的合成效果。
用户可以直接通过选择现有演员库中或上传自己的视频或者照片创建AI形象,从取代真人出镜录制的环节,再输入由其它AI工具生成的脚本和配乐,并且完全素材拼接就能直接输出视频,并且还能一键完成多国语言的转换,大大地节省了制作费用和周期。现在这类由多种AI工具组合制作的视频,已经广泛出现在了市场上.
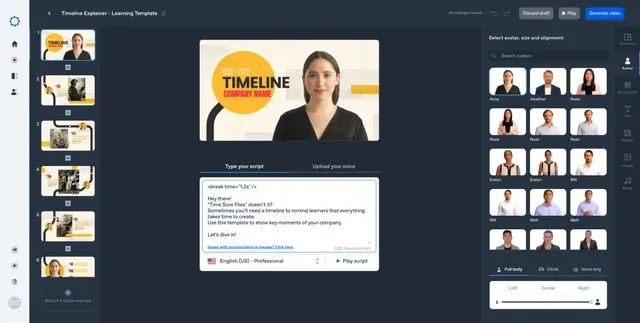
需要注意的是,D-ID虽然会自动为生成的数字人添加一系列的面部动作,并且模拟一些轻微的头部运动,但问题是表情有时候会显得比较怪异,如果你上传的照片太逼真,还可能会产生非常“恐怖”的效果。
值得一提的是,D-ID的操作难度极低,即便你完全没有视频创作的经验,也可以使用一张图片,在短短的几分钟内制作一条人物解说类的视频。
相似的AI视频创作工具还有“Synthesia”,资料显示,已经有数千家公司成为了这类产品的用户。

当然,AI工具生成视频和我们自己创作一样,同样会面临版权、伦理等问题,你无法在平台上上传涉及政治、性、犯罪、名人、歧视性等内容的图像和视频。

AI剪辑:拼接素材,套上模板秒出视频
除了上述方式,AI剪辑的功能则更见常见,如抖音的剪映、快手的快影、百度的百家号、B站的必剪等我们常用的剪辑应用里,都支持输入图片+文案后,智能一键生成视频,还可以字幕和配音,甚至还可以一键翻译。

文案我们可以通过ChatGPT直接完成,然后输入剪映,在搭配收集到的图片素材,例如下图:
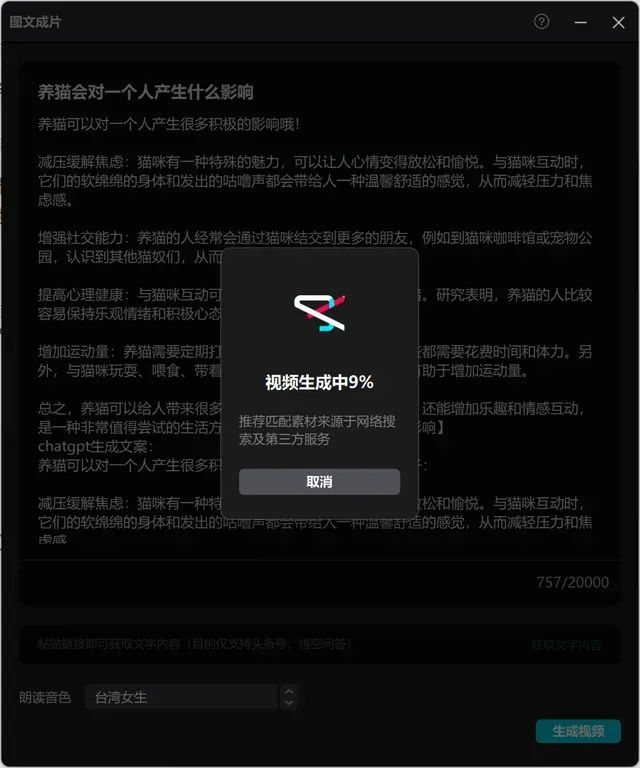
映不到一分钟,就可以自动生成视频,并且可以保证画面跟文案内容基本符合。假如你对素材有更高的要求,还有自带的在线素材库可以供你选择。
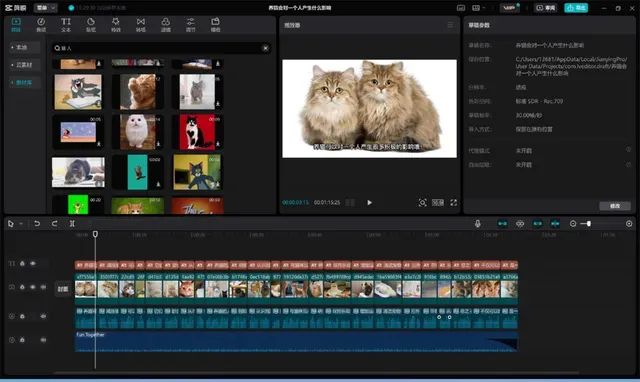
值得注意的是,因为版权的原因,这些素材往往来自于Unsplash、Pexels等第三方免版权图库,
AI剪辑所完成的工作,只是对文案以及图片/视频进行分析后,做分镜头处理,智能匹配文字和相应的画面。

图源Lumen5
此外,类似于AI剪辑工具还有主打长图文转视频“Lumen5”,不仅有大量的视频模板可供用户选择,操作的门槛也更低,你只需要制作PPT一样拖曳文字即可转成画面。
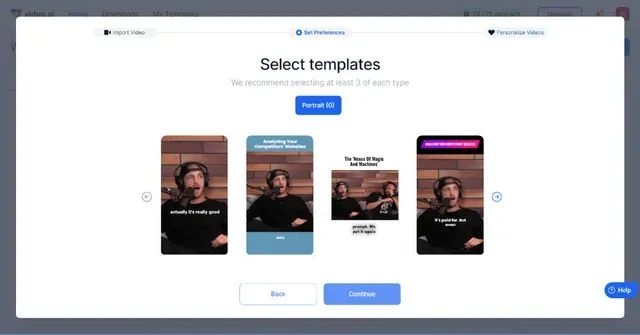
还有同时适用于直播视频切片和播客剪辑,来自印度AI初创团队的“vidyo”,不仅支持长视频转短视频,还能够通过AI语音识别技术自动从素材中剪辑出精彩片段。
唯一的问题是,其视频语言目前仅支持英文,当然我们也可以使用其它的工具进行二次翻译。
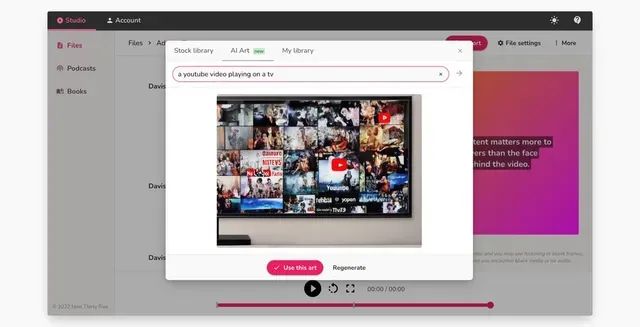
当然上面的两款甚至大部分视频创作软件的AI功能,都还局限于自动匹配文字和视频素材,但是这并不妨碍我们对AIGC工具未来的期待。
海外的AI视频工具“Fliki”就成功突破了这一限制,不仅支持短图文转换视频,还能够通过输入Twitter等博客链接的方式快速合成短视频,此外还拥有文字生成AI图像的功能。
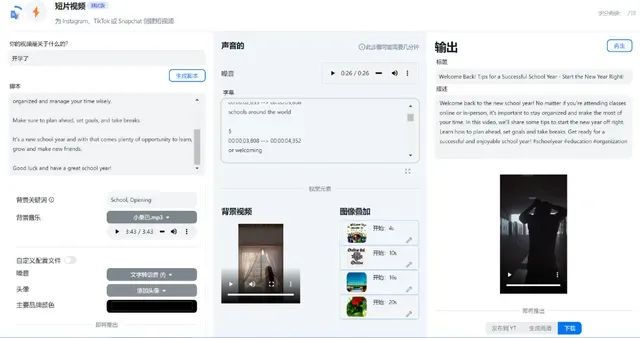
而目前来说,技术上最强的还是海外的AI视频网站“QuickVid”,它已经集成L1CHATGPT、DALL·E 2等AI生成图文的能力,你只需要为它指定一个主题,就可以自动完成接下来的所有工作。
不过它的问题是,在二次编辑上的自由度和丰富性比较有限。
除了这一类AI剪辑工具之外,还有“Video Enhance AI”等视频增强软件,可以帮助提升视频的画质和分辨率。

跨模态AI:一句话做视频
“Copydone”是国内一家AIGC初创公司开发的AI工具,能够完成小红书、淘宝等各大平台营销文案的生成,还能够生成的文案自动生成配图或拼接视频,也就是说,你甚至不需要自己准备文案和图文素材。
虽然这一类工具的视频生成,还有能够明显看出的模板性,其原创度还有待观望,但是但更强大的跨模态生成视频的AI工具,马上就来了。

2022年5月,清华大学就联合智源研究院开发并发布了“CogVideo”,这是国内首个开源的文本生成视频模型,在其Demo网站中,你只需要在旁边对其下达指令,就能够生成对应的视频。
虽然目前来说,限制性还很强,比如能够输入的指令还很少,且只能够生成4秒且分辨率为480×480的视频
但这一技术已经实现了让AI拥有更接近于人类的工作方式,就像AI绘画模型一样学习文本和图像的抽象概念。

在海外的AI视频网站“Kaiber”上,用户可以选择自己输入图像或文本描述,也可以从预设中选择几个词,就能快速生成4种视频结果。
美国流行摇滚乐队Linkin Park发布的新MV《Lost》,就是由Kaiber为其制作的动画。
据Meta官网介绍,“Make-A-Video”加速了文本到视频模型的训练(它不需要从头开始学习视觉和多模态表示),也不需要成对的文本-视频数据,就可以利用丰富的文字生成视频,图像生成视频(让单个图像或两个图像间动起来),以及改变原始视频的风格。
谷歌发布的“Imagen Video”和“Phenaki”也能实现类似以上的效果,并且Phenaki可以根据一系列提示生成2分钟以上的长视频。

总的来说,现在的AI视频类工具还是有很大的限制和缺陷,只能算是辅助视频创作的小助手。
李彦宏曾经说到过AICG的三个发展阶段:助手阶段、协作阶段、原创阶段
在第一阶段,AIGC将辅助人类进行内容生产;
第二阶段,AIGC以虚实并存的虚拟人形态出现,形成人机共生的局面;
第三阶段则是原创阶段,AIGC将独立完成内容创作。Gartner预计,到2025年,生成式人工智能将占所有生成数据的10%。
就目前来看,AICG已经进入了第二阶段,距离第三阶段还为时尚早吗?
我们可以预见在未来其对于内容创作者的冲击会有多大,AIGC 已经并且将继续颠覆了内容创作的方式,且永远不可逆转。

但是诚如视频中“乔布斯”在视频中讲的那样:
人工智能虽然很强大,但是也有其局限性,它永远无法取代人情味,也永远无法真正理解人类体验的复杂性。
而对于内容创作者来说,要做的也绝不是排斥他,而是去接受并掌握他。利用其高效的工作效率,让我们从琐碎的工作中解放出来,而有更多时间专注于真正重要的事情。
同时,我们必须不断提高自己的能力和思维,以确保它一直是人类成长和发展的工具,而不是我们人类的替代品。












